Last weekend at FOSDEM I presented in the Internet of Things (IoT) devroom,
showing how one can use MsgFlo with Flowhub to visually live-program devices that talk MQTT.
If the video does not work, try the alternatives here. See also full presentation notes, incl example code.
Background
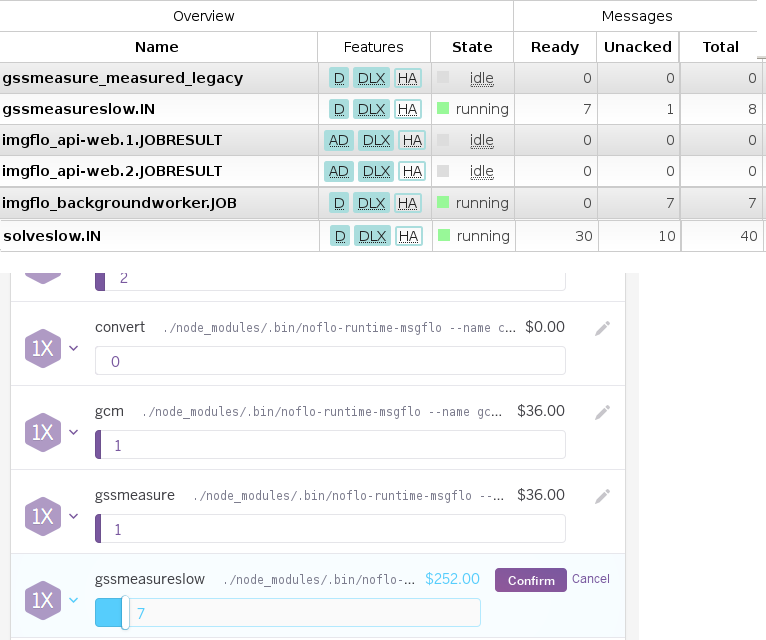
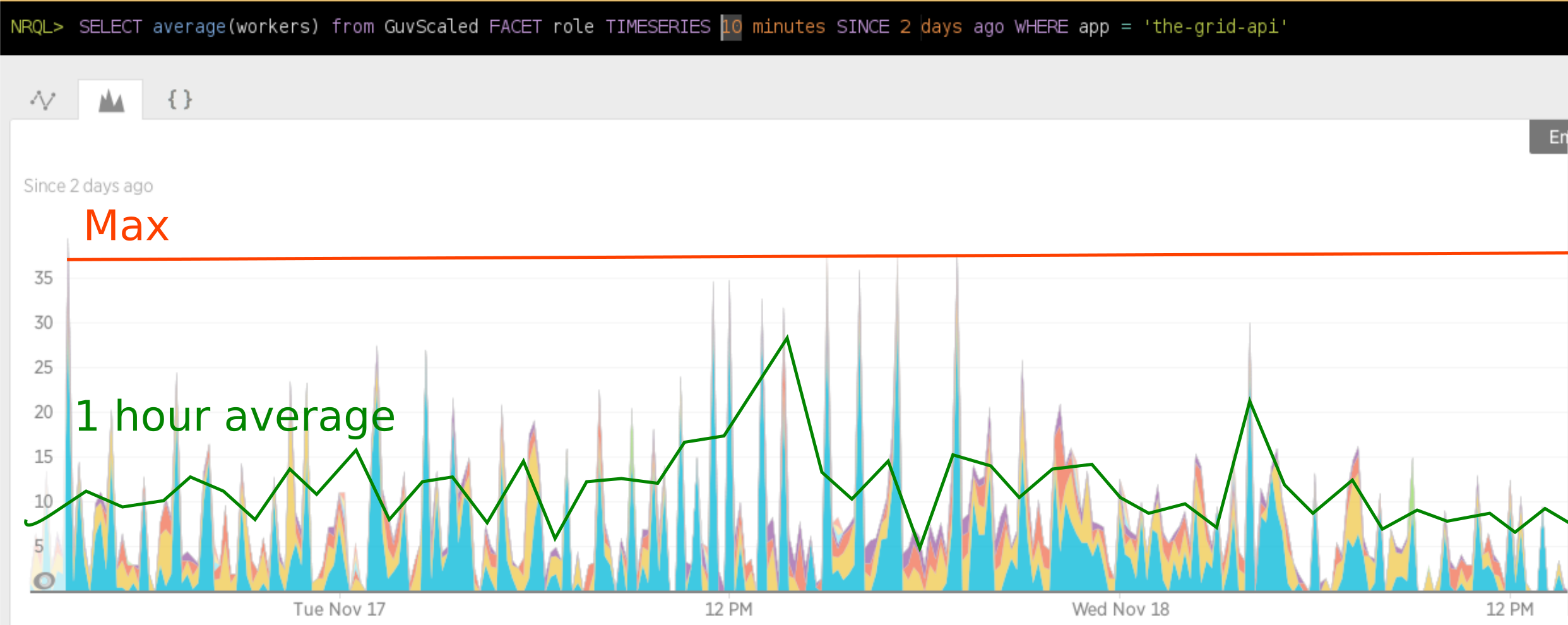
Since announcing MsgFlo in 2015, it has mostly been used to build scalable backend systems (“cloud”), using AMQP and RabbitMQ. At The Grid we’ve been processing hundred thousands of jobs each week, so that usecase is pretty well tested by now.
However, MsgFlo was designed from the beginning to support multiple messaging systems (including MQTT), as well as other kinds of distributed systems – like a networks of embedded devices working together (one aspect of “IoT”). And in MsgFlo 0.10 this is starting to work pretty nicely.
Visual system architecture
Typical MQTT devices have the topic names hidden in code. Any documentation is typically kept in sync (or not…) by hand.
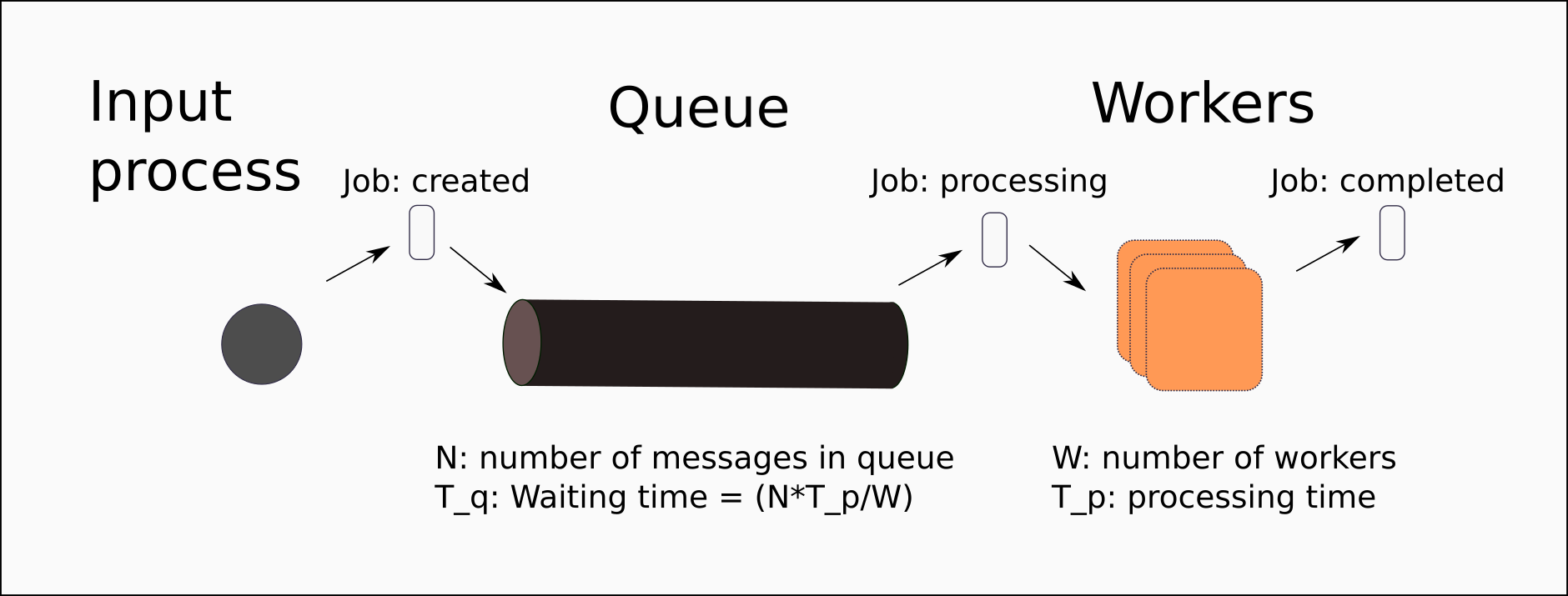
MsgFlo lets you represent your devices and services as FBP/dataflow “components”, and a system as a connected graph of component instances. Each device periodically sends a discovery message to the broker. This message describing the role name, as well as what ports exists (including the MQTT topic name). This leads to a system architecture which can be visualized easily:
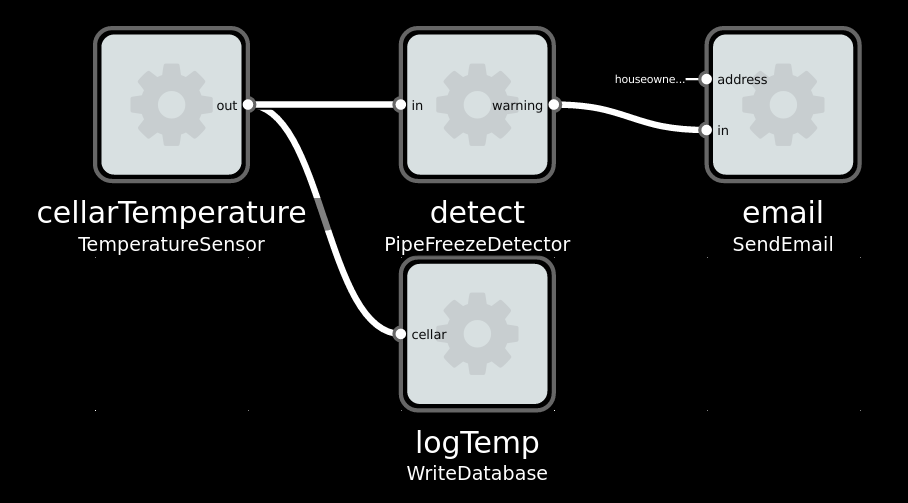
Imaginary solution to a typically Norwegian problem: Avoiding your waterpipes freezing in the winter.
Rewire live system
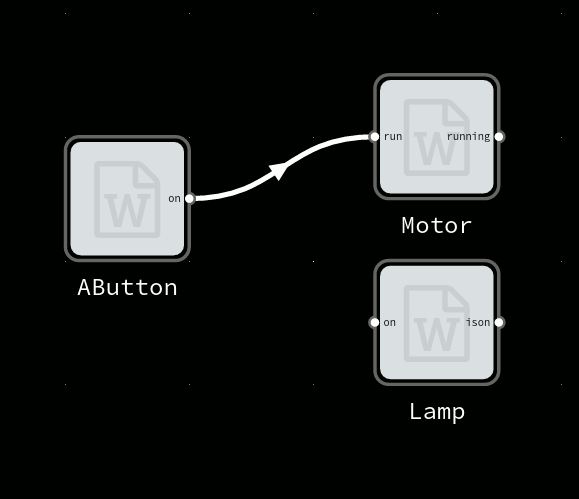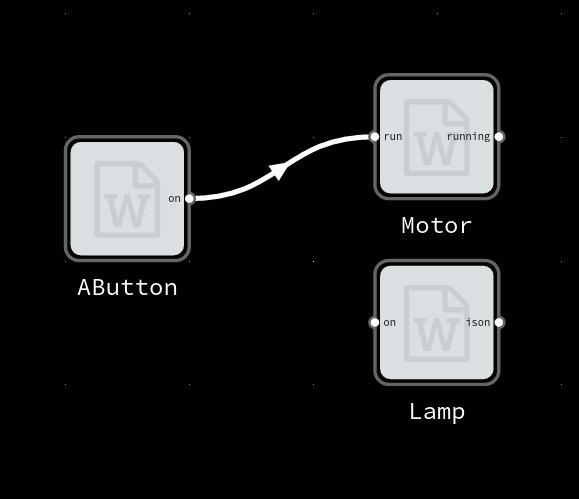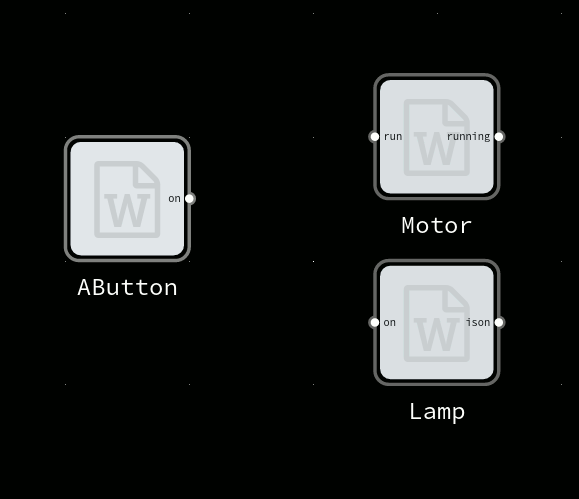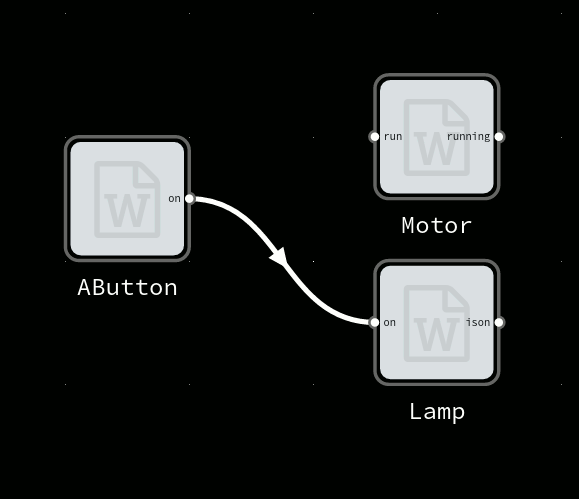
In most MQTT devices, output is sent directly to the input of another device, by using the same MQTT topic name. This hardcodes the system functionality, reducing encapsulation and reusability.
MsgFlo each device *should* send output and receive inports on topic namespaced to the device.
Connections between devices are handled on the layer above, by the broker/router binding different topics together. With Flowhub, one can change these connections while the system is running.
Change program values on the fly
Changing a parameter or configuration of an embedded device usually requires changing the code and flashing it. This means recompiling and usually being connected to the device over USB. This makes the iteration cycle pretty slow and tedious.
In MsgFlo, devices can (and should!) expose their parameters on MQTT and declare them as inports.
Then they can be changed in Flowhub, the device instantly reflecting the new values.
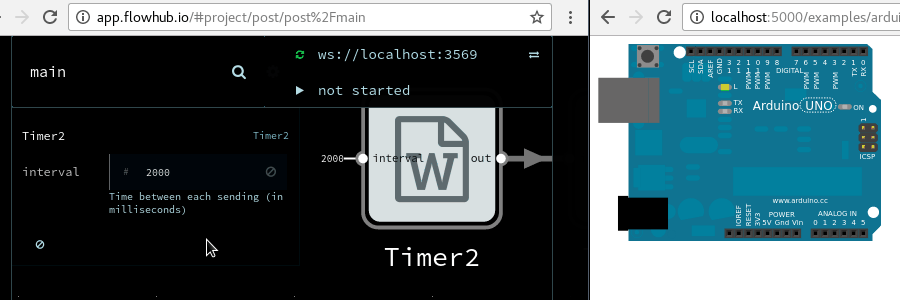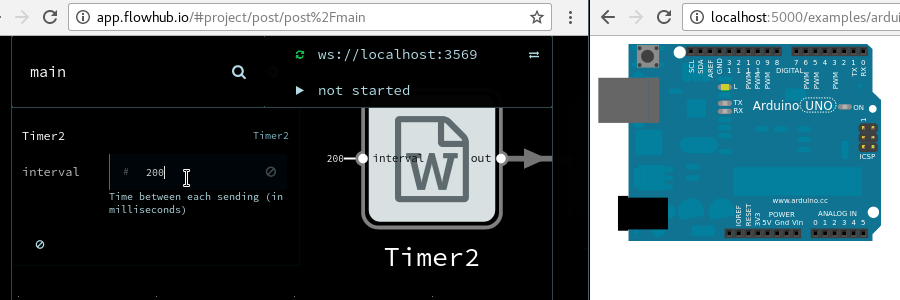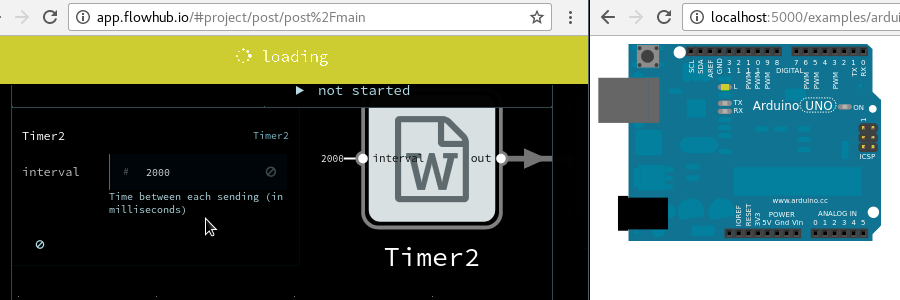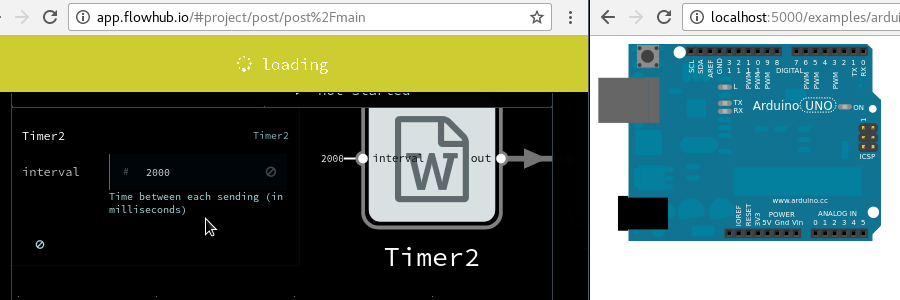
Great for exploratory coding; quickly trying out different values to find the right one.
Examples are when tweaking animations or game mechanics, as it is near impossible to know up front what feels right.
Add component as adapters
MsgFlo encourages devices to be fairly stupid, focused on a single generally-useful task like providing sensor data, or a way to cause actions in the real world. This lets us define “applications” without touching the individual devices, and adapt the behavior of the system over time.
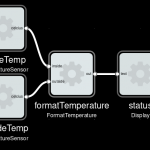
Imagine we have a device which periodically sends current temperature, as a floating-point number in Celcius unit. And a display device which can display text (for instance a small OLED). To show current temperature, we could wire them directly:
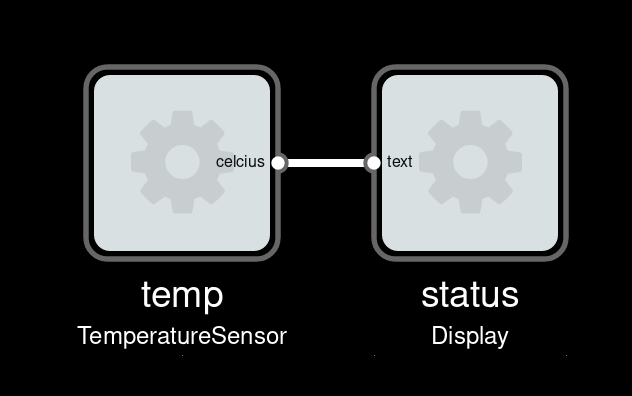
Our display would show something like “22.3333333”. Not very friendly, how does one know what this number means?
Better add a component to do some formatting.
Adding a Python component
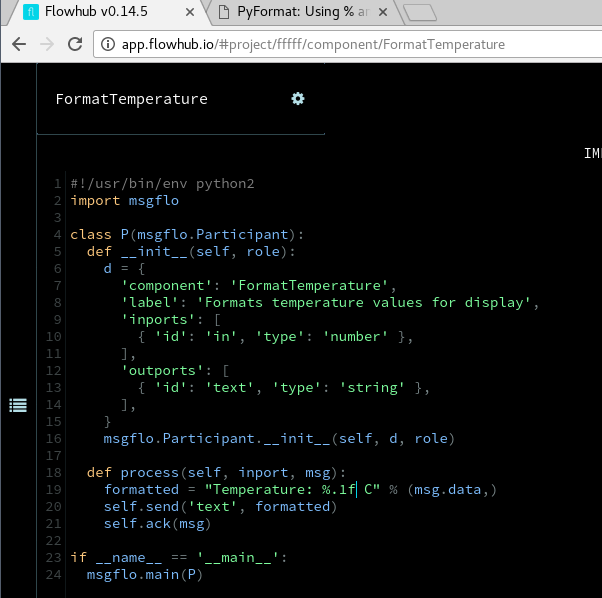
Component formatting incoming temperature number to a friendly text string
And then insert it before the display. This will create a new process, and route the data through it.
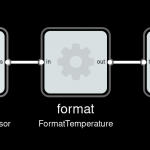
Our display would now show “Temperature: 22.3 C”
Over time maybe the system grows further
Added another sensor, output now like “Inside 22.2 C Outside: -5.5 C”.
Getting started with MsgFlo
If you have existing “things” that support MQTT, you can start using MsgFlo by either:
1) Modifying the code to also send the discovery message.
2) Use the msgflo-foreign-participant tool to provide discovery without code changes
If you have new things, using one of the MsgFlo libraries is a quick way to support MQTT and MsgFlo. Right now there are libraries for Python, C++11, Node.js, NoFlo and Arduino.